手機端生成模型爆發在即,芯片迎來鉅變?
本文來自格隆匯專欄:半導體行業觀察;作者:李飛
以生成式模型(generative model)為代表的下一代AI正在席捲科技行業乃至整個人類社會。目前,人們對於生成式模型的關注還主要在於以OpenAI和谷歌為代表的人工智能巨頭運行在雲端服務器的模型,這些模型需要巨大的算力,並且一般運行在GPU上。然而,隨着技術的發展,我們認為生成式模型運行在手機端已經到了一個轉折點,馬上會進入大規模鋪開的階段。
在看具體技術之前,我們不妨先看一下,用户對於運行在手機端的生成式模型有哪些具體應用場景。這期是值得我們仔細考慮,因為像ChatGPT這樣的人工智能對話應用並不需要真正運行在手機終端——讓ChatGPT完成文稿設計這樣的需求的最佳使用場景還是在接入互聯網的電腦上,而不是運行在手機本地。我們認為,最適合生成式模型運行在手機終端芯片上的第一是拍攝增強,包括超分辨、去模糊、照片補全等,這些應用需要模型能在任何時候都能低延遲地運行,因此需要在本地執行。另一個任務是智能助理,指的是通過運行一個大模型去檢索所有用户本地的備忘錄、短信記錄等,通過綜合用户所有的個人信息來實現智能助理的功能——例如如果檢測到用户和某個聯繫人最近的短信是關於約在飯店吃飯,助理可以自動設置一個提醒信息,等等。由於涉及到用户隱私,因此這類模型也需要運行在手機本地的芯片上。
對於用於拍攝增強的生成式模型主要是以擴散(diffusion)模型為代表的圖像生成式模型。擴散模型在去年一年中取得了長足的進步,其生成內容的質量足以改變用户的拍攝體驗,包括:
1、超分辨:使用擴散模型可以把低分辨率的圖片以很高的質量轉換成高分辨率圖像,其質量遠高於目前已有的其他模型。
2、圖像修補:包括把圖像中不想要的內容去除/更換(即inpainting),或者把圖片內容進一步補全(即outpainting)。
對於基於擴散模型的生成式圖像模型,自從Stable Diffusion從去年下半年發佈之後,已經獲得了業界極大的關注。擴散模型一般的模型都較大,而且需要運行多步的採樣過程,之前雖然也有運行在手機上的例子,但是因為運行時間過程(10秒左右),尚未得到真正大規模應用。然而,隨着今年10月份中國清華團隊發表了latent consistency model(LCM)的研究論文,在手機上運行高性能圖像生成式模型已經不再遙不可及。

LCM模型和Stable Diffusion的模型結構類似,但是LCM通過數學上的優化,可以把一次生成需要的模型執行次數從Stable Diffusion的50次降低到2-4次,相當於把端到端的運行速度提升了10倍,而且生成圖像的質量和Stable Diffusion接近。目前,LCM已經在人工智能社區得到了廣泛的關注和應用,我們認為很快LCM就會成為手機上運行圖像生成式模型的首選,而且LCM的低延遲可以真正實現全新的用户體驗;例如,高質量的實時超分辨可以讓數字變焦得到的拍攝質量和光學變焦相似,但是同時又避免了厚重的鏡頭;又如,inpainting/outpainting可以讓用户快速編輯拍攝的照片並分享,能實現在手機上擁有和photoshop相似的效果,這也將會大大提升用户體驗。
對於智能助理應用來説,目前主要還處於探索階段,如何將多模態的信息(包括用户的短信、備忘錄、日曆等等)整合在一起並不容易,但是我們認為最終模型的形態最有可能還是類似GPT這樣的大語言模型,通過海量數據與訓練來實現對於用户數據的深入理解並且給出相應幫助。這類智能助手的第一步落地應用可能是用户消息編輯和改寫,例如用户可以讓智能助手去改寫一條短信以改變語氣,這樣的應用預計在明年就會落地。
手機生成式模型需要什麼樣的芯片
首先,我們從用於拍攝增強的圖像生成式模型(LCM)開始分析,因為這類模型的應用較為明確。
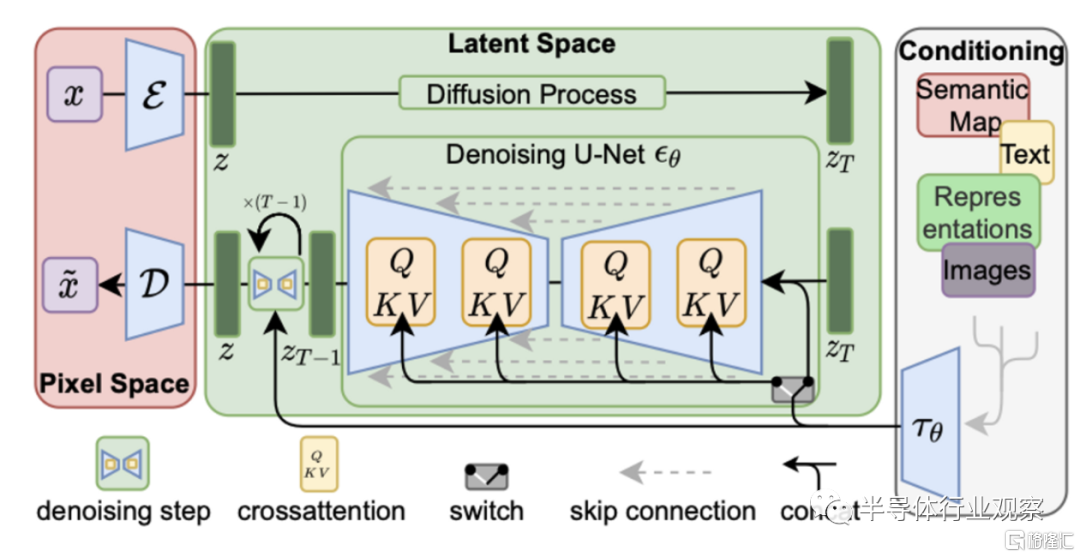
我們對於模型芯片支持的分析可以從算符、算力和內存三方面來入手。從算符來看,LCM或者Stable Diffusion模型使用的算符主要是常用的卷積和注意力(attention)層,這些算符在目前的手機芯片人工智能加速器中已經得到了非常好的支持。而在算力和內存方面,圖像生成式模型的複雜度和模型尺寸都比現有的運行在手機上的人工智能模型要大一到兩個數量級:LCM的參數量達到了10億以上,而相對而言目前主流手機人工智能模型的參數量都在千萬左右。如我們之前所説的,手機需要能實時執行這樣的模型,因此需要在算力上滿足模型的需求。
算力能滿足需求可以從兩方面來考慮,首先是增加人工智能加速器的峯值算力,主要的方法就是增加計算單元的數量。但是,計算單元數量的增加是以更大的芯片面積(即更高的成本)為代價的,為了能在成本和性能之間得到一個較好的折衷,需要能使用“性價比”更好的計算單元。在服務器的LCM版本中,使用的計算是基於32位或者16位浮點數的,但是在手機端執行時32/16位浮點數計算單元太貴,因此絕大多數的計算必須使用更低精度,例如8位定點數,或者8位浮點數9甚至是4位浮點數)。這裏就涉及到了一個軟硬件協同設計的問題,即如何在使用低精度計算的條件下同時確保模型輸出質量不受太大影響,具體是使用8位浮點數還是8位定點數性價比更高等等,因此需要模型設計團隊和芯片設計團隊合作才能完成。另外,由於模型的尺寸遠大於之前的主流模型到達了GB數量級,因此很可能需要手機的DRAM容量進行升級才能較好的支持。
除了DRAM容量之外,模型參數量大也意味着對於內存接口的壓力更大(否則可能會陷入內存牆問題,讓內存訪問成為整體模型執行速度的瓶頸)。從這個角度,一方面可望將會推動手機芯片加速使用下一代內存接口(例如LPDDR6),而在另一方面也推動SoC使用更多的片上內存(SRAM)來緩解DRAM訪問的壓力。最後,在Stable Diffusion和LCM模型中廣為使用的U-Net神經網絡結構也擁有更多的中間結果(activation),為了能確保最佳的延遲和能效比,這也需要SoC片上有更多的SRAM來滿足需求。
對於大語言模型來説,其對於手機芯片的需求也可以從算符、算力和內存來看。同樣,算符方面大語言模型使用的主要算符是attention,目前已經得到廣泛支持;主要挑戰則是大語言模型的參數量甚至比擴散模型/LCM更大一個數量級,到了百億數量級,這對於手機內存容量和接口速度都將造成巨大的挑戰,而如果大語言模型真的能在手機得到大規模應用,預計將會大大推動手機芯片內存容量和內存接口的發展。此外,由於大語言模型的參數量太大,很有可能需要多級緩存,每次只會有一部分模型參數加載在DRAM中,還會有一部分會留在非易失性存儲器中,因此內存和非易失性存儲器的接口速度提升可能也會得到推動。
生成式模型對手機芯片市場的潛在影響
目前,我們看到手機系統廠商已經越來越重視生成式模型在手機端的應用。在最近的發佈會上,知名手機廠商vivo和Oppo都把這類生成式模型作為下一代新手機的主要賣點,原因很簡單,因為目前生成式模型已經到了能夠真正成為核心用户體驗的時刻了,而且模型技術也足夠成熟,爆發在即。
手機芯片格局也可能會在這次的生成式模型熱潮中發生微妙的改變。生成式模型的支持能力可能會成為和手機鏡頭一樣重要的核心硬件賣點,但是生成式模型的最終解決方案其實是一個軟硬件結合設計的方案,這樣來説,其實對於有自研芯片能力的手機廠商來説是非常有利的,因為這些手機廠商可以通過同時掌握模型和硬件的設計,從而實現最高效率的解決方案,或者換句話説有可能通過深度的協同優化,即使在芯片實現工藝和性能較為落後的情況下,仍然實現很好的用户體驗,這一點對於一些中國的手機廠商例如華為來説尤其有利,因為他們同時擁有深度的人工智能模型開發、手機系統優化和芯片開發能力,通過在自研的第一方應用(例如拍照以及照片瀏覽)應用中加入自研的模型跑在自研的芯片上,有機會充分利用端到端優化的機會。
對於為手機系統提供芯片平台的公司例如高通和聯發科來説,則需要提供完整的參考設計。在這方面,高通已經把手機端生成式模型提到了核心位置,在最近發佈的Snapdragon 8 Gen 3中,高通宣佈可以實現以低於一秒的延遲實現Stable Diffusion圖像生成,未來可望進一步提升質量並降低延遲,接下來就看使用高通芯片的手機系統廠商如何利用這樣的算力了。聯發科也基於億級參數大語言模型的特性,開發了混合精度 INT4 量化技術,結合公司特有的內存硬件壓縮技術NeuroPilot Compression,以更高效地利用內存帶寬,大幅減少AI大模型佔用終端內存,為端側運行AI大語言模型突破手機內存限制,助力更大參數模型在端側落地。
另一個疑問是,雲端生成式模型芯片領域目前的統治者Nvidia會如何看待手機生成式模型的機會?Nvidia在移動端的嘗試自從十多年前的Tegra系列之後似乎就停滯了,但是今年年中Nvidia傳出和聯發科合作並且下一代聯發科旗艦手機SoC可能會使用Nvidia GPU的消息,可見Nvidia在手機生成式模型領域還是有機會能切入。Nvidia在這個領域的優勢主要在於模型開發生態,但是在手機生態(包括第一方應用)中是否繼續這樣的優勢,還需要聯合SoC廠商以及使用該SoC的手機系統廠商深度合作,這樣的合作能進行到什麼樣的程度,還需拭目以待。